写一个解释器
大学的时候我学的最懵的一门计算机相关课程大概就是《编译原理》。各种什么LL(1),乔姆斯基文法之类的术语实在让我不明觉厉。后来虽然大概了解了一点各种语言如何工作的原理,但是还从来没有自己动手造过与编译原理相关的轮子。
最近工作常用 Java,我考虑用 Java 写点什么来练手(其实是上班摸鱼写其它语言太不和谐了),这时候就想到了不如写一个解释器。实际上一个最基本的,基于 Tree-Walking 算法的编程语言解释器是很简单的。另外,本文仅仅是一篇流水账,如果你对具体设计细节感兴趣,我的解释器基本是按照 Writing An Interpreter In Go 的设计思路来写的,只不过语言换成了 Java。
我的代码在:https://github.com/chenlx0/JMonkey
开始之前
在流行的编程语言里,以解释器形式实现的有 PHP, Python, Ruby, lua … 等等(有些语言的官方版本现在已经不再是以解释器的形式实现了,但至少早期是) 。这些语言都很……灵活,具有动态类型和各种丰富的数据结构。接下来我们要实现的这门语言叫做 Monkey,也是一门灵活的动态语言。这门语言并没有啥既定的规范……看起来像那么回事就行:P
我实现的版本具有的大致特点是:支持 if 判断和 while 循环;具有 bool, int, float, string, array(线性表), dict(哈希表)这些数据结构;支持函数,递归,闭包。
举个例子,这个语言大概长这个样子:
let fib = fn(x) {
if (x <= 2) {
return 1;
}
return fib(x-1) + fib(x-2);
};
let funcDict = {"fib": fib};
funcDict["fib"](10);
那么一个解释器由哪几个部分组成呢?它们是 词法解析器(Lexer),语法解析器(Parser),求值器(Evaluator)。
词法解析器负责把输入的代码转换成词法单元(Token),语法解析器负责把这一连串符号转换成抽象语法树(Abstract Syntax Tree),最后求值器遍历获得的抽象语法树求值。
词法解析
其实词法分析和语法分析都是理论复杂,但手写出一个能用的没那么难的东西。而且实际造一门语言的时候,我们一般会采用一些生成器来帮助我们生成词法分析和语法分析相关的代码。最常用的用来生成词法分析器和语法分析器的工具大概是 Lex 和 Yacc,很多流行的语言都是用的它俩。
词法分析器本质上是个状态机,它逐个字符检查输入的文本,如果匹配到了关键字或运算符,就生成对应的词法单元。比如对于下述代码:
let a = fn(x) {
return 3 + x / 1.5;
};
词法分析器用简单的模式匹配把它分割为如下的词法单元:
"let", "a", "=", "fn", "(", "x", ")", "{", "return", "3", "+", "x", "/", "1.5", ";", "}", ";"
其中 let, fn, return 都是关键字,而 a, x 都是变量。可以采用 Enum 或者各种结构体来表示不同类型的词法单元。
同时我们可以在自定义的词法单元的结构里加上当前所读取的位置之类的信息,方便后续报错的时候我们可以在错误信息里指出当前出问题的代码位置。
每种语言都有对应的状态机。拿最简单的来说,我们常用的 JSON 也有一个状态机,有兴趣可以看看官方文档里的状态机长什么样:https://www.json.org/json-en.html
语法分析
抽象语法树
获取到输入代码的词法单元后,我们下一步需要根据它来生成抽象语法树(以下简称 AST)。AST 其实就是一种能够代表我们代码结构的树状数据结构。在 Monkey 语言中,AST 节点有两种:一种是 Statement,这种节点不会向上传递值。比如 let 语句和函数体都是 Statement,我们的代码就是由一系列 Statement 组成的;另一种是 Expression,这种节点会向上传递值, 比如单个的数字、字符串、数组,还有加减乘除这些运算都属于 Expression。
对于我们刚刚生成的词法单元,对应的 AST 应该长这样:
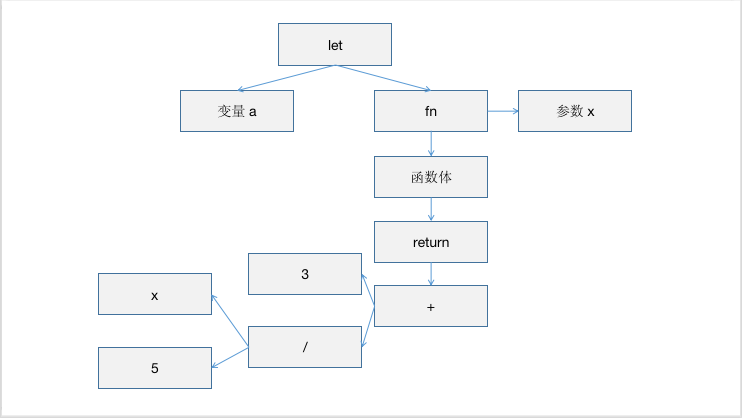
在这里忍不住提一波 Lisp 语言。如果我们要实现的是一种 Lisp 语言的话,生成AST 的难度会小很多。因为 Lisp 的语法简直就是在手写 AST。
自顶向下的语法分析
自顶向下的语法分析方法是最最简单的一种语法分析方法。它通过递归求解来构造 AST。例如我们读到了词法单元 let,那么我们期待接下来会读到一个词法单元 变量 和 =,然后再解析一个 Expression。
通过递归生成 AST 其实效率会比较差。有一种更好的,采用回溯法的语法分析算法被称为自底向上分析法,但这一算法实现难度比较大。
但还有一个麻烦的问题。注意 3 + x / 1.5 这个表达式,我们的语法分析器如何能正确地根据算符优先级解析这个运算式?
Pratt 算符优先级算法
实际实现中,为了解决算符优先的问题,采用了 Pratt 算法。
我们针对每个中缀运算符赋予了一个算符优先值,中缀运算符除了加减乘除之外还包括了函数调用时的 “(“,取下标时的 “[” 这些符号。我们解析中缀运算符时会和前一个被解析的中缀运算符优先级做比较,来决定所生成树的结构。
这要细说又能说一篇文章了,再挂个链接出来:https://www.oilshell.org/blog/2016/11/01.html
求值
终于简单地概括完词法和语法分析的部分。接下来我们就该考虑如何根据 AST 去实现求值了 (Evaluate)。
虽然求值器才是一个解释器的核心部分,但我不太想细讲。求值器的核心想法在 SICP 这本书中的第三章已经很详细地讲过,还有 Coursera 上华盛顿大学的公开课 Programming Language 中也深入讨论了这个过程。
如果你了解过树这种数据结构的各种操作的话,看到 AST 的结构,你可能自然而然地就想到了如何递归地求解诸如 1 + 2 * 3 这样的表达式!我们从树底开始遍历各个节点求值……是的,这就是 Tree-Walking 的基本思想!
在开始写算法之前,我们还需要考虑如何在求值器中表示我们的数据结构。如果你用的是 C 或者 Go 这样的语言,你可能还需要为 Monkey 封装一套类型系统。幸运的是,Java 的类型系统挺完善的,使用 Object 来表示 Moneky 的类型已经够了。同时 Java 的自动装箱拆箱也让我们少了很多事。不过实际写代码的时候会用到很多反射,这也会让我们解释器的效率比较低。
但除了什么字符串、数字、布尔变量这些东西外,我们还是需要特别在代码里封装一种类型:函数。
我们的函数不只是简单的像 if 语句里的那种代码块,它还需要支持递归和闭包。比如下面这个求 Fibonacci 值的例子:
let gen_fib = fn(s) {
let fib = fn(x) {
if (x <= 2) { return s; }
return fib(x-1) + fib(x-2);
}
return fib;
}
gen_fib(1)(10);
为了让我们的求值器能运行这个例子,我们需要引入一个新的概念:环境 (Environment)
我们的代码在运行时,都有一个「堆栈」,我们的变量,各种值都在这个堆栈里。环境就是来扮演这个堆栈的角色。每当我们调用函数时,这个函数本身都具有一个环境。实际上,在 Monkey 里,环境就是一个哈希表,它记录当前赋值的变量。
对于每个函数节点,它也有自己的一个环境。每当我们要查找某个变量的值时,会遍历当前函数节点及其所有父节点的环境,直到找到当前变量对应的值。这样一来,递归和闭包的基本特性也就被实现了。
总结
其实这篇文章就是个写解释器的流水账,记录一下我实现整个解释器的大致流程。另外特别推荐一下 Writing an Interpreter in Go, Writing a Compiler in Go 这两本小册子,用精练的笔法告诉了读者解释器和编译器,虚拟机的本质。学习编译原理的时候,一上来就看龙书指定是看不懂的,看完这种 learning by doing 的小册子之后再来看龙书,才知道它讲的是啥玩意,另外也比较容易抓住对自己日常工作有帮助的重点。